What Is a Distributed System?
A distributed system is essentially a collection of multiple computers (called nodes) that work together seamlessly to behave like a single system from the user’s perspective. These nodes communicate through networks using protocols such as HTTP, gRPC, or message buses to coordinate tasks, share data, and deliver results instantly.
For example, when you use YouTube, one service streams video, another suggests what to watch next, and yet another manages comments. They all run independently but cooperate flawlessly to provide a smooth user experience. With Uber, your location tracking, driver matching, and pricing calculations are handled by separate services working in tandem. This division of labor allows enormous platforms to scale and maintain reliability.
Why Not Just Use One Server?
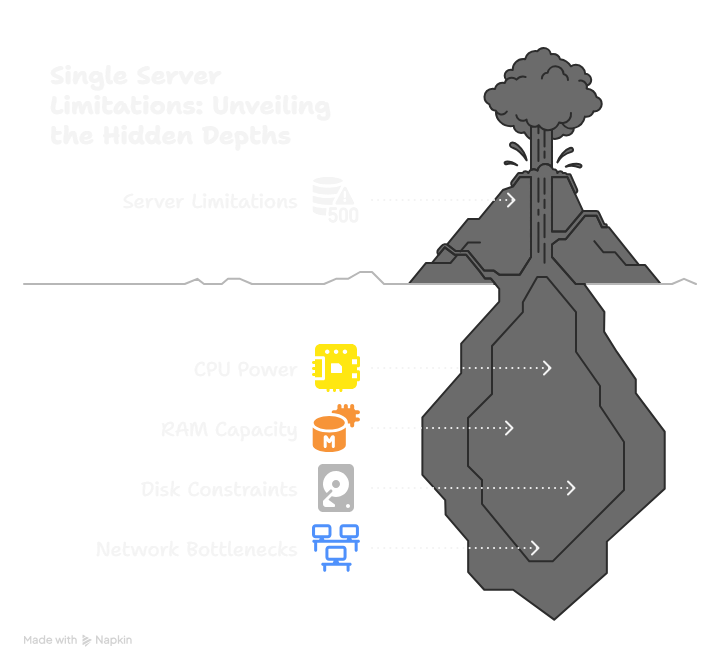
Most applications start out simple: a single server running everything — the app, the database, all the logic. Up to a point, this is fine. But as your system’s traffic grows, just upgrading that one server with more CPU, memory, or storage — called vertical scaling — hits limits. It’s like widening a highway: after a certain width, you can’t physically add more lanes. Plus, a single server is a single point of failure — if it crashes or becomes overloaded, your entire service goes down.
Key limitations of a single server include:
- Finite CPU power (how many computations it can do)
- Limited RAM (how much data it can keep in immediate memory)
- Disk space and speed constraints
- Network throughput bottlenecks
When you hit these ceilings, performance degrades, requests time out, and crashes happen randomly.